Run on YARN
- Introduction
- Running on YARN: Quickstart
- Application Master UI
- Configuration
- Coordinator Internals
Introduction
Apache YARN is part of the Hadoop project and provides the ability to run distributed applications on a cluster. A YARN cluster minimally consists of a Resource Manager (RM) and multiple Node Managers (NM). The RM is responsible for managing the resources in the cluster and allocating them to applications. Every node in the cluster has an NM (Node Manager), which is responsible for managing containers on that node - starting them, monitoring their resource usage and reporting the same to the RM.
Applications are run on the cluster by implementing a coordinator called an ApplicationMaster (AM). The AM is responsible for requesting resources including CPU, memory from the Resource Manager (RM) on behalf of the application. Samza provides its own implementation of the AM for each job.
Running on YARN: Quickstart
We will demonstrate running a Samza application on YARN by using the hello-samza example. Lets first checkout our repository.
git clone https://github.com/apache/samza-hello-samza.git
cd samza-hello-samza
git checkout latest
Set up a single node YARN cluster
You can use the grid script included as part of the hello-samza repository to setup a single-node cluster. The script also starts Zookeeper and Kafka locally.
./bin/grid bootstrap
Submitting the application to YARN
Now that we have a YARN cluster ready, lets build our application. The below command does a maven-build and generates an archive in the ./target folder.
./bin/build-package.sh
You can inspect the structure of the generated archive. To run on YARN, Samza jobs should be packaged with the following structure.
samza-job-name-folder
├── bin
│ ├── run-app.sh
│ ├── run-class.sh
│ └── ...
├── config
│ └── application.properties
└── lib
├── samza-api-0.14.0.jar
├── samza-core_2.11-0.14.0.jar
├── samza-kafka_2.11-0.14.0.jar
├── samza-yarn_2.11-0.14.0.jar
└── ...
Once the archive is built, the run-app.sh script can be used to submit the application to YARN’s resource manager. The script takes 2 CLI parameters - the config factory and the config file for the application. As an example, lets run our FilterExample on YARN as follows:
$ ./deploy/samza/bin/run-app.sh --config-factory=org.apache.samza.config.factories.PropertiesConfigFactory --config-path ./deploy/samza/config/filter-example.properties
Congratulations, you’ve successfully submitted your first job to YARN! You can view the YARN Web UI to view its status.
Application Master UI
The YARN RM provides a Web UI to view the status of applications in the cluster, their containers and logs. By default, it can be accessed from localhost:8088 on the RM host.

In addition to YARN’s UI, Samza also offers a REST end-point and a web interface for its ApplicationMaster. To access it, simply click on the Tracking UI link corresponding to your application. Samza’s Application Master UI provides you the ability to view:
Job-level runtime metadata - eg: JMX endpoints, running JVM version
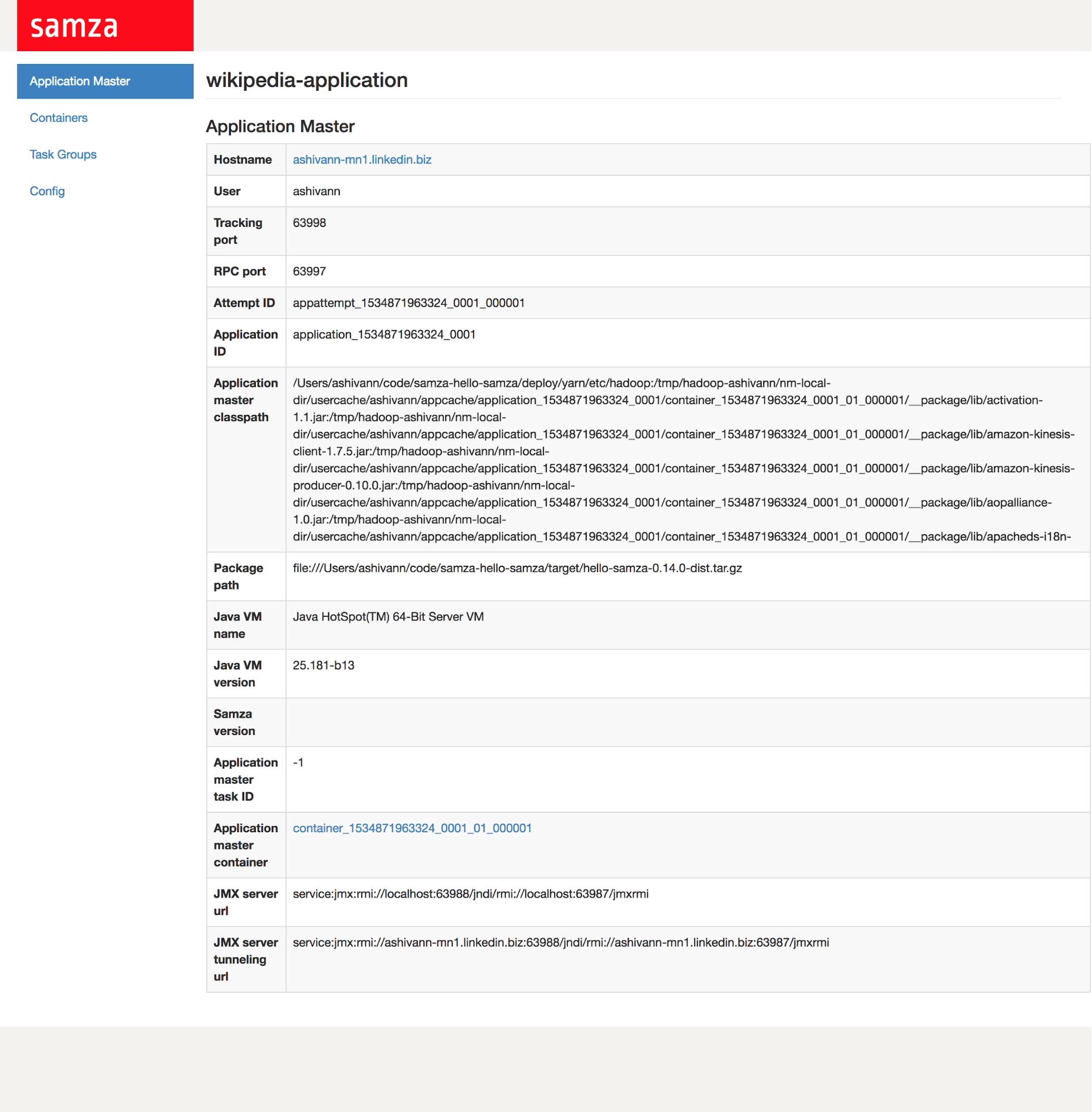
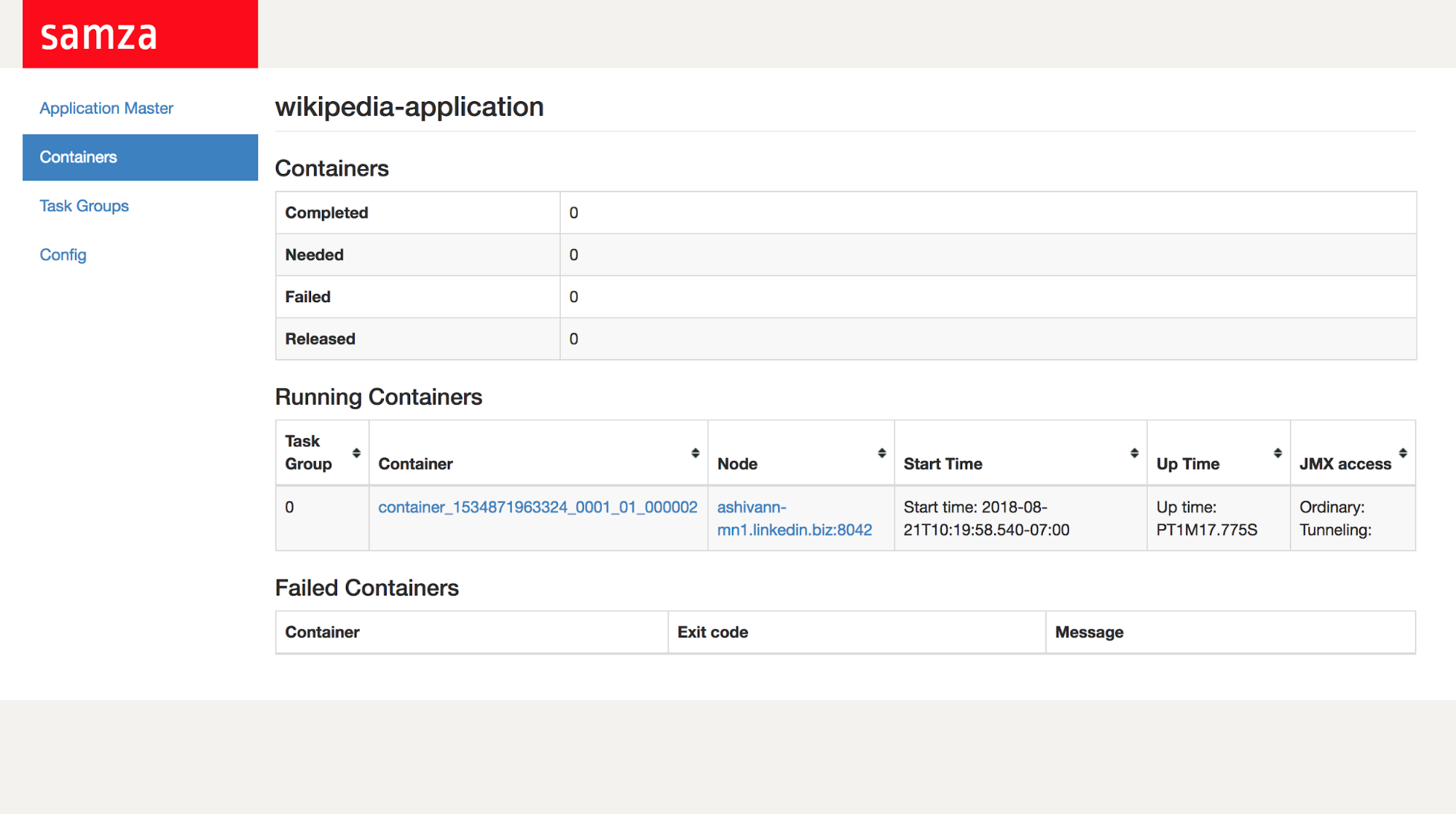
Information about individual containers eg: their uptime, status and logs
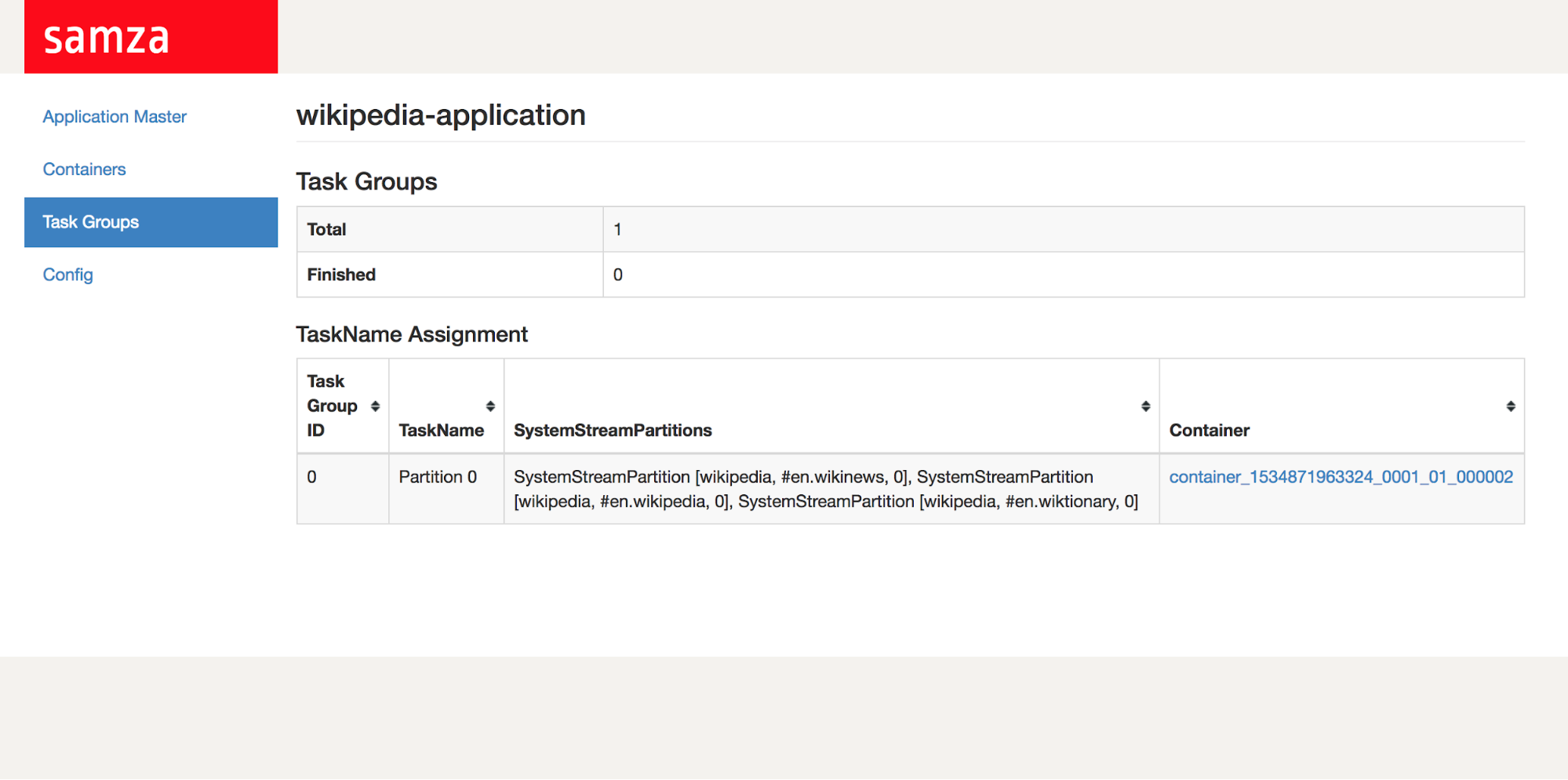
Task Groups eg: Information on individual tasks, where they run and which partitions are consumed from what host
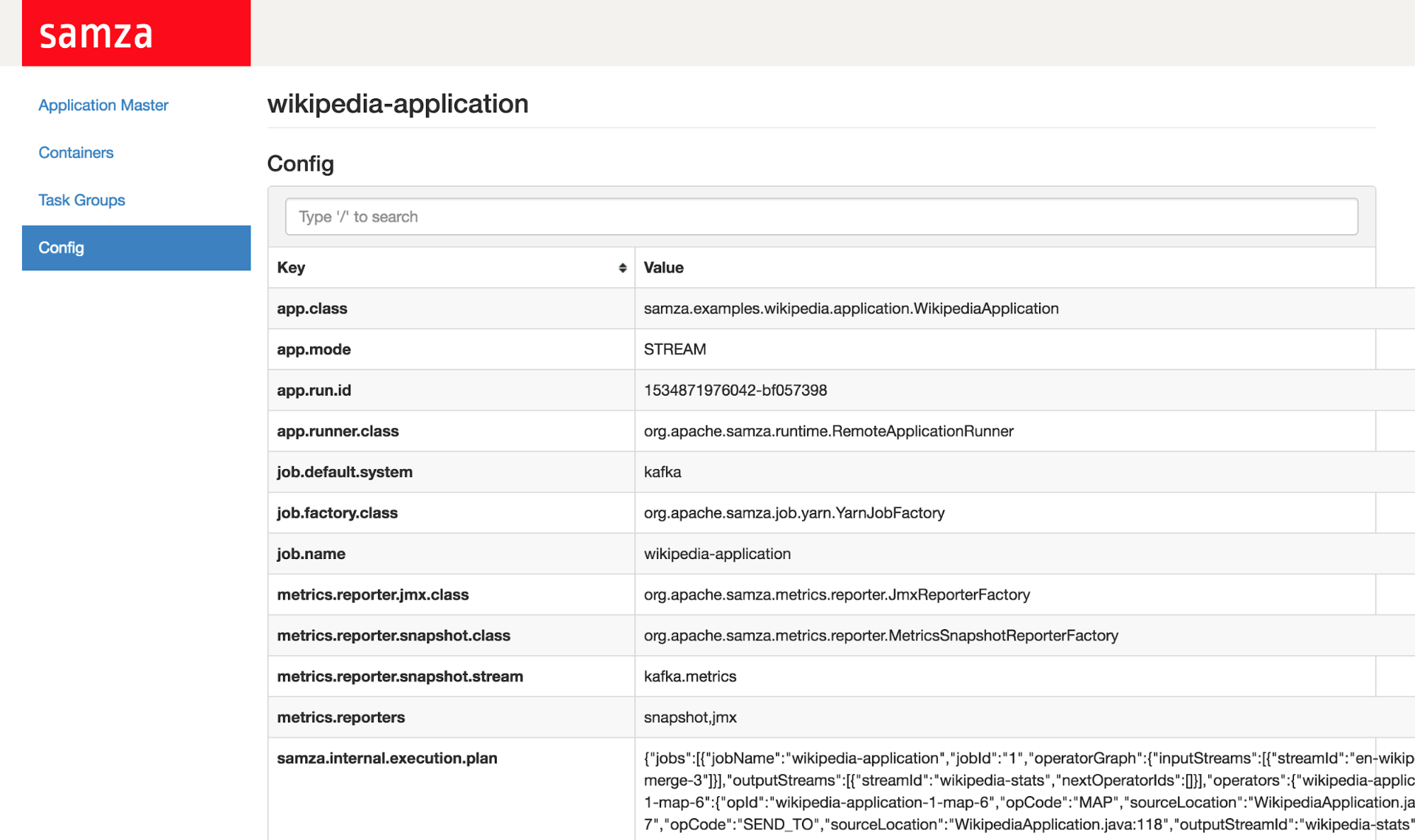
Runtime configs for your application
Configuration
In this section, we’ll look at configuring your jobs when running on YARN.
Configuring parallelism
Recall that Samza scales your applications by breaking them into multiple tasks. On YARN, these tasks are executed on one or more containers, each of which is a Java process. You can control the number of containers allocated to your application by configuring cluster-manager.container.count. For example, if we are consuming from an input topic with 5 partitions, Samza will create 5 tasks, each of which process one partition. Tasks are equally distributed among available containers. The number of containers can be utmost the number of tasks - since, we cannot have idle containers without any tasks assigned to them.
Configuring resources
Samza jobs on YARN run on a multi-tenant cluster and should be isolated from each other. YARN implements isolation by enforcing limits on memory and CPU each application can use.
Memory
You can configure the memory-limit per-container using cluster-manager.container.memory.mb and memory-limit for the AM using yarn.am.container.memory.mb. If your container process exceeds its configured memory-limits, it is automatically killed by YARN.
CPU
Similar to configuring memory-limits, you can configure the maximum number of vCores (virtual cores) each container can use by setting cluster-manager.container.cpu.cores. A vCore is YARN’s abstraction over a physical core on a NodeManager which allows for over-provisioning. YARN supports isolation of cpu cores using Linux CGroups.
Configuring retries
Failures are common when running any distributed system and should be handled gracefully. The Samza AM automatically restarts containers during a failure. The following properties govern this behavior.
cluster-manager.container.retry.count: This property determines the maximum number of times Samza will attempt to restart a failed container within a time window. If this property is set to 0, any failed container immediately causes the whole job to fail. If it is set to a negative number, there is no limit on the number of retries.
cluster-manager.container.retry.window.ms: This property determines how frequently a container is allowed to fail before we give up and fail the job. If the same container has failed more than cluster-manager.container.retry.count times and the time between failures is less than this property, then Samza terminates the job. There is no limit to the number of times we restart a container, if the time between failures is greater than cluster-manager.container.retry.window.ms.
YARN - Operations Best practices
Although this section is not Samza specific, it describes some best practices for running a YARN cluster in production.
Resource Manager high-availability
The Resource Manager (RM) provides services like scheduling, heartbeats, liveness monitoring to all applications running in the YARN cluster. Losing the host running the RM would kill every application running on the cluster - making it a single point of failure. The High Availability feature introduced in Hadoop 2.4 adds redundancy by allowing multiple stand-by RMs.
To configure YARN’s ResourceManager to be highly available Resource Manager, set your yarn-site.xml file with the following configs:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
Reserving memory for other services
Often, other services including monitoring daemons like Samza-REST run on the same nodes in the YARN cluster. You can configure yarn.nodemanager.resource.system-reserved-memory-mb to control the amount of physical memory reserved for non-YARN processes.
Another behaviour to keep in mind is that the Resource Manager allocates memory and cpu on the cluster in increments of yarn.scheduler.minimum-allocation-mb and yarn.scheduler.minimum-allocation-vcores. Hence, requesting allocations that are not multiples of the above configs will cause internal fragmentation.
NodeManager work-preserving recovery
Often, NMs have to be bounced in the cluster for upgrades or maintenance reasons. By default, bouncing a Node Manager kills all containers running on its host. Work-preserving NM Restart enables NodeManagers to be restarted without losing active containers running on the node. You can turn on this feature by setting yarn.nodemanager.recovery.enabled to true in yarn-site.xml. You should also set yarn.nodemanager.recovery.dir to a directory where the NM should store its state needed for recovery.
Configuring state-store directories
When a stateful Samza job is deployed in YARN, the state stores for the tasks are located in the current working directory of YARN’s attempt. YARN’s DeletionService cleans up the working directories after an application exits. To ensure durability of Samza’s state, its stores need to be persisted outside the scope of YARN’s DeletionService. You can set this location by configuring an environment variable named LOGGED_STORE_BASE_DIR across the cluster.
To manage disk space and clean-up state stores that are no longer necessary, Samza-REST supports periodic, long-running tasks named monitors.
Configuring security
You can run Samza jobs on a secure YARN cluster. YARN uses Kerberos as its authentication and authorization mechanism. See this article for details on operating Hadoop in secure mode.
Management of Kerberos tokens
One challenge for long-running applications on YARN is how they periodically renew their Kerberos tokens. Samza handles this by having the AM periodically create tokens and refresh them in a staging directory on HDFS. This directory is accessible only by the containers of your job. You can set your Kerberos principal and kerberos keytab file as follows:
# Use the SamzaYarnSecurityManagerFactory, which fetches and renews the Kerberos delegation tokens when the job is running in a secure environment.
job.security.manager.factory=org.apache.samza.job.yarn.SamzaYarnSecurityManagerFactory
# Kerberos principal
yarn.kerberos.principal=your-principal-name
# Path of the keytab file (local path)
yarn.kerberos.keytab=/tmp/keytab
By default, Kerberos tokens on YARN have a maximum life-time of 7 days, beyond which they auto-expire. Often streaming applications are long-running and don’t terminate within this life-time. To get around this, you can configure YARN’s Resource Manager to automatically re-create tokens on your behalf by setting these configs in your yarn-site.xml file.
<property>
<name>hadoop.proxyuser.yarn.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.yarn.groups</name>
<value>*</value>
</property>
Samza Coordinator Internals
In this section, we will discuss some of implementation internals of the Samza ApplicationMaster (AM).
The Samza AM is the control-hub for a Samza application running on a YARN cluster. It is responsible for coordinating work assignment across individual containers. It includes the following componeents:
- YARNClusterResourceManager, which handles interactions with YARN and provides APIs for requesting resources and starting containers.
- ContainerProcessManager, which uses the above APIs to manage Samza containers - including restarting them on failure, ensuring they stay in a healthy state.
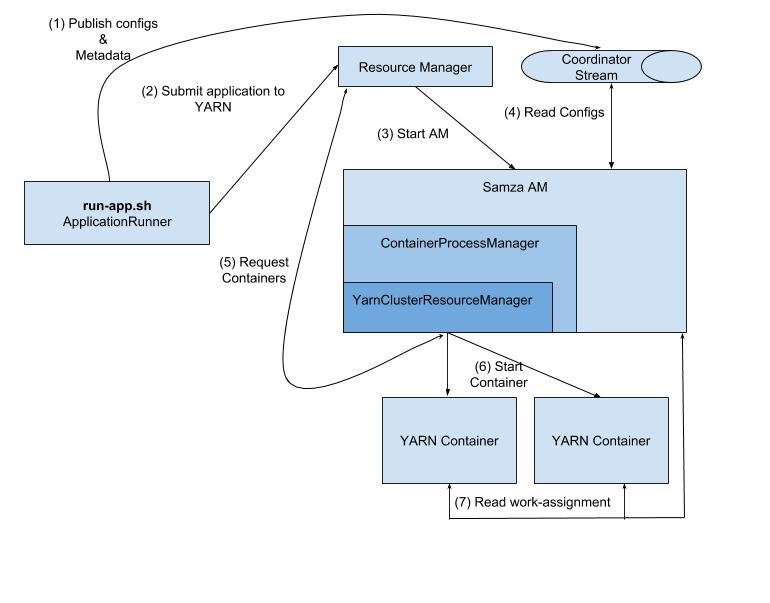
Here’s a life-cycle of a Samza job submitted to YARN:
The
run-app.shscript is started providing the location of your application’s binaries and its config file. The script instantiates an ApplicationRunner, which is the main entry-point responsible for running your application.The ApplicationRunner parses your configs and writes them to a special Kafka topic named - the coordinator stream for distributing them. It proceeds to submit a request to YARN to launch your application.
The first step in launching any YARN application is starting its Application Master (AM).
The ResourceManager allocates an available host and starts the Samza AM.
The Samza AM is then responsible for managing the overall application. It reads configs from the Coordinator Stream and computes work-assignments for individual containers.
It also determines the hosts each container should run on taking data-locality into account. It proceeds to request resources on those nodes using the
YARNClusterResourceManagerAPIs.Once resources have been allocated, it proceeds to start the containers on the allocated hosts.
When it is started, each container first queries the Samza AM to determine its work-assignments and configs. It then proceeds to execute its assigned tasks.
The Samza AM periodically monitors each container using heartbeats and ensure they stay alive.