Samza Table API
Introduction
Samza Table API is an abstraction for data sources that support random access by key, which simplifies stream-table-join. It is the natural evolution of the existing [storage API] (https://github.com/apache/samza/blob/master/samza-kv/src/main/scala/org/apache/samza/storage/kv/KeyValueStorageEngine.scala), and it offers support for both local and remote data sources and composition through hybrid tables.
For various reasons, a real-time stream often only contain minimal or a small amount of information, and may need to be augmented with richer information fetched from adjunct data sources through joining. This is quite common in advertising, relevance ranking, fraud detection, and other domains. However, there exists a wide variety of data stores with different characteristics and levels of sophistication. Samza Table API simplifies the application developer experience by hiding the details of individual technologies, while making it easier to migrate from one technology to another.
For remote data sources, the Samza remote table provides optimized access such as caching, rate-limiting, retry and batching (future) support.
In addition, more advanced functionalities can be provided through table composition. For example, bootstrapping a stream is often used to build an authoritative local cache, and today stream processing has to wait until bootstrap is completed. A hybrid table can provide access to remote data source while the local cache is being built, so that stream processing could begin earlier.
Application developers can now take advantage of the aforementioned benefits, which are all encapsulated under the Samza Table API.
Sample Applications
Sample applications demonstrating how to use Samza Table API can be found [here] (https://github.com/apache/samza-hello-samza/tree/latest/src/main/java/samza/examples/cookbook).
Architecture and Concepts
The diagram below illustrates the overall architecture of Samza Table API.

Let’s look at a few concepts before diving into the API.
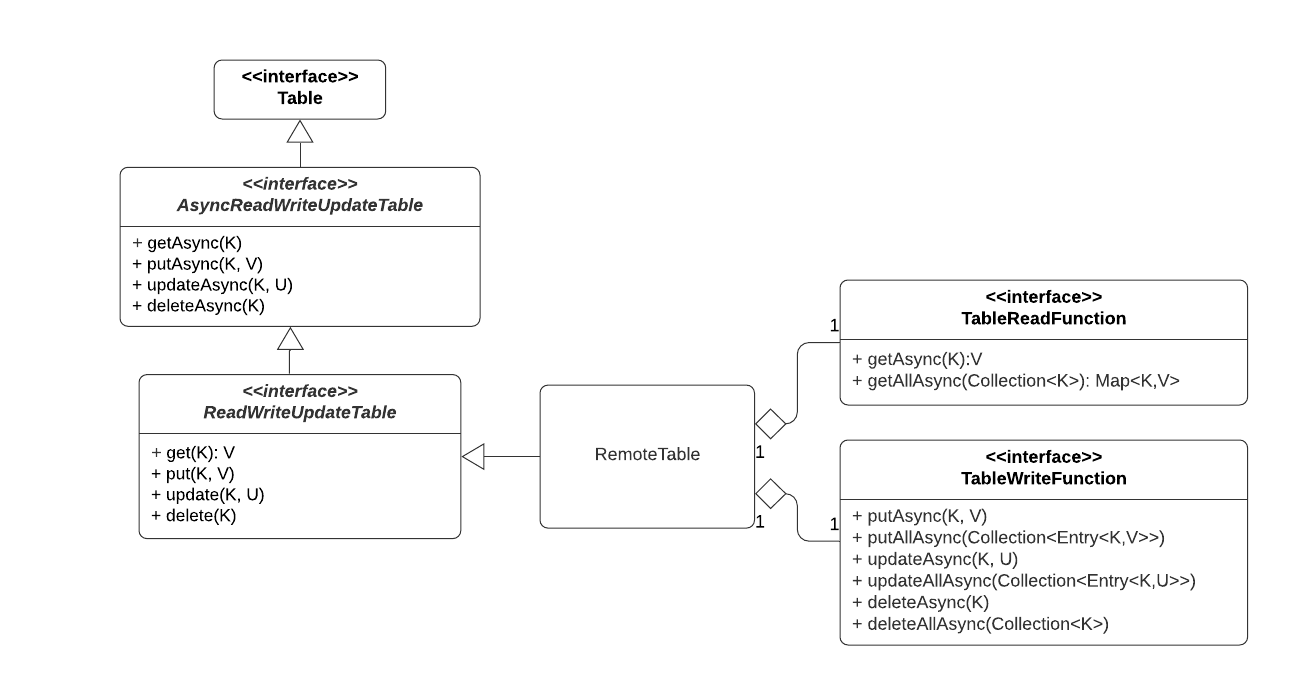
[Table] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/Table.java) -
This interface represents a dataset that can be accessed by key. We support
gets, put, updates and deletes. A table can be accessed either
synchronously or asynchronously and a request may contain one or more keys.
There are three broad categories of tables: local, remote and hybrid.
[AsyncReadWriteUpdateTable] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/AsyncReadWriteUpdateTable.java) -
Interface that represents a read-write-update table with asynchronous operations. Core interface for all table implementations.
[ReadWriteUpdateTable] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/ReadWriteUpdateTable.java) -
Interface that represents a read-write-update table. It implements AsyncReadWriteUpdateTable. Supports synchronous operations as well.
[TableDescriptor] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/operators/TableDescriptor.java) -
User-facing object that contains metadata that completely describes a table.
It may include identifier, serialization, provider, configuration, etc.
Example implementations of this interface are
- [
RemoteTableDescriptor] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/table/remote/RemoteTableDescriptor.java) facilitates access to remotely stored data, - [
InMemoryTableDescriptor] (https://github.com/apache/samza/blob/master/samza-kv-inmemory/src/main/java/org/apache/samza/storage/kv/inmemory/InMemoryTableDescriptor.java) describes a table stored in-memory, and - [
RocksDbTableDescriptor] (https://github.com/apache/samza/blob/master/samza-kv-rocksdb/src/main/java/org/apache/samza/storage/kv/RocksDbTableDescriptor.java) describes a table stored in RocksDB.
Table Sync and Async API
Samza Table supports both synchronous and asynchronous API. Below is an example for
the get operation.
/**
* Gets the value associated with the specified {@code key}.
*
* @param key the key with which the associated value is to be fetched.
* @param args additional arguments
* @return if found, the value associated with the specified {@code key}; otherwise, {@code null}.
* @throws NullPointerException if the specified {@code key} is {@code null}.
*/
V get(K key, Object ... args);
/**
* Asynchronously gets the value associated with the specified {@code key}.
*
* @param key the key with which the associated value is to be fetched.
* @param args additional arguments
* @return completableFuture for the requested value
* @throws NullPointerException if the specified {@code key} is {@code null}.
*/
CompletableFuture<V> getAsync(K key, Object ... args);Using Table with Samza High Level API
The code snippet below illustrates the usage of table in Samza high level API.
1 class SamzaStreamApplication implements StreamApplication {
2 @Override
3 public void describe(StreamApplicationDescriptor appDesc) {
4 TableDescriptor<Integer, Profile> desc = new InMemoryTableDescriptor(
5 "t1", KVSerde.of(new IntegerSerde(), new ProfileJsonSerde()));
6
7 Table<KV<Integer, Profile>> table = appDesc.getTable(desc);
8
9 appDesc.getInputStream("PageView", new NoOpSerde<PageView>())
10 .map(new MyMapFunc())
11 .join(table, new MyJoinFunc())
12 .sendTo(anotherTable);
13 }
14 }
15
16 static class MyMapFunc implements MapFunction<PageView, KV<Integer, PageView>> {
17 private ReadWriteUpdateTable<Integer, Profile> profileTable;
18
19 @Override
20 public void init(Config config, TaskContext context) {
21 profileTable = (ReadWriteUpdateTable<Integer, Profile>) context.getTable("t1");
22 }
23
24 @Override
25 public KV<Integer, PageView> apply(PageView message) {
26 return new KV.of(message.getId(), message);
27 }
28 }
29
30 static class MyJoinFunc implements StreamTableJoinFunction
31 <Integer, KV<Integer, PageView>, KV<Integer, Profile>, EnrichedPageView> {
32
33 @Override
34 public EnrichedPageView apply(KV<Integer, PageView> m, KV<Integer, Profile> r) {
35 counterPerJoinFn.get(this.currentSeqNo).incrementAndGet();
36 return r == null ? null : new EnrichedPageView(
37 m.getValue().getPageKey(), m.getKey(), r.getValue().getCompany());
38 }
39 }In the code snippet above, we read from an input stream, perform transformation, join with a table and finally write the output to another table.
- Line 4-5: A
TableDescriptorfor an in-memory table is created, and then the serde is set. - Line 7: A table object is created from the
TableDescriptor; internally, theTableDescriptoris converted to aTableSpec, and registered with theTaskApplicationDescriptor. The table object has a reference to theTableSpec. - Line 9: creates an
InputStream - Line 10: applies a map operator defined in line 16-28, all table instances
can be accessed from the task context in
Task.init(). In this example, it is stored in a local variable. - Line 11: joins the mapped stream with the table using the supplied join function defined in lines 30-39.
- Line 12: writes the join result stream to another table
Using Table with Samza High Level API using Side Inputs
The code snippet below illustrates the usage of table in Samza high level API using side inputs.
1 class SamzaStreamApplication implements StreamApplication {
2 @Override
3 public void describe(StreamApplicationDescriptor appDesc) {
4 TableDescriptor<Integer, Profile> desc = new InMemoryTableDescriptor(
5 "t1", KVSerde.of(new IntegerSerde(), new ProfileJsonSerde()))
6 .withSideInputs(ImmutableList.of(PROFILE_STREAM))
7 .withSideInputsProcessor((msg, store) -> {
8 Profile profile = (Profile) msg.getMessage();
9 int key = profile.getMemberId();
10 return ImmutableList.of(new Entry<>(key, profile));
11 });
12
13 Table<KV<Integer, Profile>> table = appDesc.getTable(desc);
14
15 appDesc.getInputStream("PageView", new NoOpSerde<PageView>())
16 .map(new MyMapFunc())
17 .join(table, new MyJoinFunc())
18 .sendTo(anotherTable);
19 }
21 }
22
23 static class MyMapFunc implements MapFunction<PageView, KV<Integer, PageView>> {
24 private ReadWriteUpdateTable<Integer, Profile> profileTable;
25
26 @Override
27 public void init(Config config, TaskContext context) {
28 profileTable = (ReadWriteUpdateTable<Integer, Profile>) context.getTable("t1");
29 }
30
31 @Override
32 public KV<Integer, PageView> apply(PageView message) {
33 return new KV.of(message.getId(), message);
34 }
35 }
36
37 static class MyJoinFunc implements StreamTableJoinFunction
38 <Integer, KV<Integer, PageView>, KV<Integer, Profile>, EnrichedPageView> {
39
40 @Override
41 public EnrichedPageView apply(KV<Integer, PageView> m, KV<Integer, Profile> r) {
42 counterPerJoinFn.get(this.currentSeqNo).incrementAndGet();
43 return r == null ? null : new EnrichedPageView(
44 m.getValue().getPageKey(), m.getKey(), r.getValue().getCompany());
45 }
46 }The code above uses side inputs to populate the profile table.
- Line 6: Denotes the source stream for the profile table
- Line 7-11: Provides an implementation of
SideInputsProcessorthat reads from profile stream and populates the table. - Line 17: Incoming page views are joined against the profile table.
Using Table with Samza Low Level API
The code snippet below illustrates the usage of table in Samza Low Level Task API.
1 class SamzaTaskApplication implements TaskApplication {
2
3 @Override
4 public void describe(TaskApplicationDescriptor appDesc) {
5 DelegatingSystemDescriptor ksd = new DelegatingSystemDescriptor("mySystem");
6
7 TableDescriptor<Integer, Profile> tableDesc = new InMemoryTableDescriptor(
8 "t1", KVSerde.of(new IntegerSerde(), new ProfileJsonSerde()));
9 GenericInputDescriptor<Profile> profileISD = ksd.getInputDescriptor("Profile", new NoOpSerde<>());
10
11 appDesc.addTable(tableDesc);
12 appDesc.addInputStream(profileISD);
13 }
14
15
16 public class MyStreamTask implements StreamTask, InitableTask {
17 private ReadWriteUpdateTable<Integer, Profile> profileTable;
18
19 @Override
20 public void init(Config config, TaskContext context) {
21 profileTable = (ReadWriteUpdateTable<Integer, Profile>) context.getTable("t1");
22 }
23
24 @Override
25 public void process(IncomingMessageEnvelope envelope, MessageCollector collector, TaskCoordinator coordinator) {
26 String key = (String)message.getKey();
27 Profile profile = (Profile)message.getMessage();
28 profileTable.put(key, profile);
29 }
30 }In the code snippet above, we read from an input stream, perform transformation, join with a table and finally write the output to another table.
- Line 7-8: A
TableDescriptorfor an in-memory table is created with tableId “t1”, and then the serde is set. - Line 9: creates an
InputStreamDescriptor. - Line 11-12: adds
TableDescriptorandInputStreamDescriptorto theTaskApplicationDescriptor. - Line 16:
InitiableStreamTaskis implemented. - Line 21: A reference to table “t1” is obtained in the
Task.init()method. - Line 26-28: gets the profile key and record from the incoming stream and writes to the table.
[ReadWriteUpdateTable] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/ReadWriteUpdateTable.java)
or [ReadWriteUpdateTable] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/ReadWriteUpdateTable.java)
can be used in the
[StreamTask.process()] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/task/StreamTask.java#L49)
method on the table reference obtained
in the
[InitableTask.init()] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/task/InitableTask.java#L35)
method.
Table Metrics
The table below summarizes table metrics:
| Metrics | Class | Description |
|---|---|---|
num-batches |
AsyncBatchingTable |
Number of batch operations |
batch-ns |
AsyncBatchingTable |
Time interval between opening and closing a batch |
get-ns |
ReadWriteUpdateTable |
Average latency of get/getAsync() operations |
getAll-ns |
ReadWriteUpdateTable |
Average latency of getAll/getAllAsync() operations |
num-gets |
ReadWriteUpdateTable |
Count of get/getAsync() operations |
num-getAlls |
ReadWriteUpdateTable |
Count of getAll/getAllAsync() operations |
num-missed-lookups |
ReadWriteUpdateTable |
Count of missed get/getAll() operations |
read-ns |
ReadWriteUpdateTable |
Average latency of readAsync() operations |
num-reads |
ReadWriteUpdateTable |
Count of readAsync() operations |
put-ns |
ReadWriteUpdateTable |
Average latency of put/putAsync() operations |
putAll-ns |
ReadWriteUpdateTable |
Average latency of putAll/putAllAsync() operations |
num-puts |
ReadWriteUpdateTable |
Count of put/putAsync() operations |
num-putAlls |
ReadWriteUpdateTable |
Count of putAll/putAllAsync() operations |
update-ns |
ReadWriteUpdateTable |
Average latency of update/updateAsync() operations |
updateAll-ns |
ReadWriteUpdateTable |
Average latency of updateAll/updateAllAsync() operations |
num-updates |
ReadWriteUpdateTable |
Count of update/updateAsync() operations |
num-updateAlls |
ReadWriteUpdateTable |
Count of updatesAll/updateAllAsync() operations |
delete-ns |
ReadWriteUpdateTable |
Average latency of delete/deleteAsync() operations |
deleteAll-ns |
ReadWriteUpdateTable |
Average latency of deleteAll/deleteAllAsync() operations |
delete-num |
ReadWriteUpdateTable |
Count of delete/deleteAsync() operations |
deleteAll-num |
ReadWriteUpdateTable |
Count of deleteAll/deleteAllAsync() operations |
num-writes |
ReadWriteUpdateTable |
Count of writeAsync() operations |
write-ns |
ReadWriteUpdateTable |
Average latency of writeAsync() operations |
flush-ns |
ReadWriteUpdateTable |
Average latency of flush operations |
flush-num |
ReadWriteUpdateTable |
Count of flush operations |
hit-rate |
CachingTable |
Cache hit rate (%) |
miss-rate |
CachingTable |
Cache miss rate (%) |
req-count |
CachingTable |
Count of requests |
retry-count |
TableRetryPolicy |
Count of retries executed (excluding the first attempt) |
success-count |
TableRetryPolicy |
Count of successes at first attempt |
perm-failure-count |
TableRetryPolicy |
Count of operations that failed permanently and exhausted all retries |
retry-timer |
TableRetryPolicy |
Total time spent in each IO; this is updated only when at least one retry has been attempted. |
Table Types
Remote Table
RemoteTable
provides a unified abstraction for Samza applications to access any remote data
store through stream-table join in High Level Streams API or direct access in Low Level Task API. Remote Table is a store-agnostic abstraction that can be customized to
access new types of stores by writing pluggable I/O “Read/Write” functions,
implementations of
TableReadFunction and
TableWriteFunction
interfaces. Remote Table also provides common functionality, eg. rate limiting
(built-in) and caching (hybrid).
The async APIs in Remote Table are recommended over the sync versions for higher throughput. They can be used with Samza with Low Level Task API to achieve the maximum throughput.
Remote Tables are represented by class
RemoteReadWriteUpdateTable and
RemoteReadWriteUpdateTable.
All configuration options of a Remote Table can be found in the
RemoteTableDescriptor class.
Couchbase is supported as remote table. See
CouchbaseTableReadFunction and
CouchbaseTableWriteFunction.
Batching
Remote Table has built-in client-side batching support for its async executions. This is useful when a remote data store supports batch processing and is not sophisticated enough to handle heavy inbound requests.
Configuration
Batching can be enabled with RemoteTableDescriptor
by providing a BatchProvider
The user can choose:
- A
CompactBatchProviderwhich provides a batch such that the operations are compacted by the key. For update operations, the latter update will override the value of the previous one when they have the same key. For query operations, the operations will be combined as a single operation when they have the same key. - A
CompleteBatchProviderwhich provides a batch such that all the operations will be visible to the remote store regardless of the keys. - A user-defined instance of [
BatchProvider].
For each [BatchProvider], the user can config the following:
- Specify the max size the batch can grow before being closed by
withmaxBatchSize(int) - Specify the max time the batch can last before being closed by
withmaxBatchDelay(Duration)
Rate Limiting
Remote Table has built-in client-side rate limiting support in both of its sync and async executions. This is useful when a remote data store does not have server-side rate limiting or is not sophisticated enough to handle heavy inbound requests.
Configuration
Rate limiting can be enabled with RemoteTableDescriptor in two ways:
- Default:
withReadRateLimit()andwithWriteRateLimit(). The default implementation uses Guava for rate limiting and provides basic throttling on read/write rates. - User-defined instance:
withRateLimiter(). Tailored for more advanced usages, eg. custom policies and/or rate limiter libraries
Quota
For the default rate limiter, a per-container quota needs to be specified, and is divided evenly among all task instances. Application developers are expected to calculate such quota from a global quota against the number of containers.
Retry
I/O failures are not uncommon given the inherently unreliable network and complex behaviors of distributed data stores. To be fault-tolerant, Remote Table provides built-in support for retrying failed I/O operations originated from the data store clients.
Retry capability can be added to a RemoteTableDescriptor by providing a
[TableRetryPolicy] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/table/retry/TableRetryPolicy.java),
which consists of three aspects:
- Backoff/Sleep policy - fixed, random, exponential with jitters
- Termination policy - by total attempts and/or delay
- Retriable exception classification - predicate on
Throwable
By default, retry is disabled as such failed I/O operations will propagate up and the caller is expected to handle the exception. When enabled, retry is on a per-request basis such that each individual request is retried independently.
Lastly, Remote Table retry provides a set of standard metrics for monitoring.
They can be found in
[RetryMetrics] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/table/retry/RetryMetrics.java).
Supporting Additional Operations
Remote Table allows invoking additional operations on remote store that are not directly supported through the Get/Put/Delete methods. Two categories of operations are supported
- Get/Put/Delete operations with additional arguments
- Arbitrary operations through readAsync() and writeAsync()
We only mandate implementers of table functions to provide implementation for Get/Put/Delete without additional arguments. End users can subclass a table function, and invoke operations on remote store directly, if they are not supported by a table function.
1 public class MyCouchbaseTableWriteFunction<V> extends CouchbaseTableWriteFunction<V> {
2
3 public static final int OP_COUNTER = 1;
4
5 @Override
6 public <T> CompletableFuture<T> writeAsync(int opId, Object... args) {
7 if (OP_COUNTER == opId) {
8 String id = (String) args[0];
9 Long delta = Long.valueOf(args[1].toString());
10 return convertToFuture(bucket.async().counter(id, delta));
11 }
12 throw new SamzaException("Unknown opId" + opId);
13 }
14
15 public CompletableFuture<Long> counterAsync(String id, long delta) {
16 return table.writeAsync(OP_COUNTER, id, delta);
17 }
18 }
19
20 public class MyMapFunc implements MapFunction {
21
22 AsyncReadWriteUpdateTable table;
23 MyCouchbaseTableWriteFunction writeFunc;
24
25 @Override
26 public void init(Context context) {
27 table = context.getTaskContext().getTable(...);
28 writeFunc = (MyCouchbaseTableWriteFunction) ((RemoteTable) table).getWriteFunction();
29 }
30
31 @Override
32 public Object apply(Object message) {
33 return writeFunc.counterAsync(“id”, 100);
34 }
35 }The code above illustrates an example of invoking counter() operation on Couchbase.
- Line 5-13: method writeAsync() is implemented to invoke counter().
- Line 15-16: it is then wrapped by a convenience method. Notice here we invoke writeAsync() on the table, so that other value-added features such as rate limiting, retry and batching can participate in this call.
- Line 27-28: references to the table and read function are obtained
- Line 33: the actual invocation.
Local Table
A table is considered local when its data physically co-exists on the same host
machine as its running job, e.g. in memory or on disk. Local tables are particularly
useful when data needs to be accessed frequently with low latency, such as a cache.
Samza Table API supports in-memory and RocksDB-based local tables, which are based
on the current implementation of in-memory and RocksDB stores. Both tables provide
feature parity to existing in-memory and RocksDB-based stores. For more detailed
information please refer to
[RocksDbTableDescriptor] (https://github.com/apache/samza/blob/master/samza-kv-rocksdb/src/main/java/org/apache/samza/storage/kv/RocksDbTableDescriptor.java) and
[InMemoryTableDescriptor] (https://github.com/apache/samza/blob/master/samza-kv-inmemory/src/main/java/org/apache/samza/storage/kv/inmemory/InMemoryTableDescriptor.java).
For local tables that are populated by secondary data sources, side inputs can be used to populate the data.
The source streams will be used to bootstrap the data instead of a changelog in the event of failure. Side inputs and
the processor implementation can be provided as properties to the TableDescriptor.
Hybrid Table
Hybrid Table consists of one or more tables, and it orchestrates operations between them to achieve more advanced functionality. Caching support for remote table is currently built on top of hybrid Table because cache can be naturally abstracted as a table, eg. local table is also a durable cache.
Caching
Despite the convenience of remote table, it still incurs the same latency as accessing the remote store directly. Whenever eventual consistency is acceptable, Samza applications can leverage the caching support in Table API to reduce such latency in addition to using the async methods.
[CachingTable] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/table/caching/CachingTable.java)
is the generic table type for combining a cache table (Guava, RocksDb, Couchbase)
with a remote table. Both the cache and data tables are pluggable, and CachingTable
handles the interactions between them for caching semantics.
Write Policies
Caching Table supports below write policies and you can configure them with
[CachingTableDescriptor] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/table/caching/CachingTableDescriptor.java).
- Write-through: records are written to both the data store and cache
- Write-around: records are written only to data store bypassing the cache
- Useful when read-path has no locality with read-path
Synchronization
No synchronization is done between data store and cache in CachingTable because
it is very cumbersome in the async code paths. Given eventual consistency is a
presumed trade-off for enabling caching, it should be acceptable for the table
and cache to not always be in-sync. Last but not least, unsynchronized operations
in CachingTable deliver much higher throughput.
Configuration
Similar to
RateLimiter
configuration in remote table, caching can be configured in two ways:
- Default:
withCacheSize(),withReadTtl(),withWriteTtl() - Custom
CacheTableinstance:withCache()
The default
[CacheTable] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/table/caching/guava/GuavaCacheTable.java)
is an in-memory cache implemented on top of
[Guava Cache] (https://github.com/google/guava/wiki/CachesExplained).
Implementing Your Own Tables
More Concepts
[TableSpec] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/TableSpec.java)
- Internal representation of a table, containing all information about a table.
[TableProvider] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/TableProvider.java)
- Provides the underlying table implementation that conforms to Table API.
[TableManager] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/table/TableManager.java)
- Responsible for lifecycle of all table instances within a task; it is created during instantiation of Samza container.
Lifecycle of a Table
The life of a table goes through a few phases
- Declaration - at first one declares the table by creating a
TableDescriptor. In both Samza High Level Streams API and Low Level Task API, theTableDescriptoris registered with stream graph, internally converted toTableSpecand in return a reference to aTableobject is obtained that can participate in the building of the DAG. - Instantiation - during planning stage, configuration is
[generated] (https://github.com/apache/samza/blob/master/samza-core/src/main/java/org/apache/samza/execution/JobNode.java)
from
TableSpec, and the actual tables are instantiated during initialization of [Samza container] (https://github.com/apache/samza/blob/master/samza-core/src/main/scala/org/apache/samza/container/SamzaContainer.scala). - Usage - there are a few ways to access a table instance
- In Samza high level API, a reference to Table can be obtained from a
TableDescriptor, which can be used to participate in the DAG operations such as [join()] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/operators/MessageStream.java) and [sendTo()] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/operators/MessageStream.java) - In Samza high level API, all table instances can be retrieved from
TaskContextusing table-id during initialization of a [InitableFunction] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/operators/functions/InitableFunction.java). - In Samza Low Level Task API, all table instances can be retrieved from
TaskContextusing table-id during initialization of a [InitableTask] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/task/InitableTask.java).
- In Samza high level API, a reference to Table can be obtained from a
- Cleanup -
[
close()] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/ReadWriteUpdateTable.java) is invoked on all tables when a job is stopped.
Developing a Local Table
Developing a local table involves implementing a new table descriptor, provider and provider factory.
- [
TableDescriptor] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/operators/TableDescriptor.java) - this is the user facing object that contains primarily configuration parameters. In addition, a few internal methods need to be implementedgenerateTableSpecConfig()should convert parameters in the table descriptor to aMap<String, String>, so that information about a table can be transferred to aTableSpec.getTableSpec()creates aTableSpecobject, which is the internal representation of a table.
- [
TableProvider] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/table/TableProvider.java) - provides the implementation for a table. It ensures a table is properly constructed and also manages its lifecycle. Methods to implement aregenerateConfig()generates all Samza configuration relevant to the table. Note in the case of RocksDB, store configuration is also generated here.
Note:
- Since the current local table implementation relies on Samza store implementation, adding a local table requires providing the store implementation first.
Developing a Remote Table
The generic design of remote table abstracts away mach common functionality.
Therefore, adding a new remote table type is much more straightforward than
writing a Samza table from scratch. You only need to implement the
TableReadFunction and
TableWriteFunction
(if supported) interfaces, and the new table type is readily usable with the
Remote Table framework.

Since the interfaces have sufficient javadocs and are self-explanatory, we present a high-level guideline to call out some less obvious aspects and help ensure consistency among future I/O (Read/Write) function implementations in the following sections.
Serializability
Samza Remote Table I/O function interfaces extend java.io.Serializable, which imposes
a serializability expectation on their implementations, i.e.
- All fields within I/O function classes must be serializable.
- Non-serializable fields must be marked transient. Otherwise, serialization of I/O function will fail. Typical examples of such fields are store client objects.
- Consequently, non-serializable fields must be initialized within the implementation of the init() method of the InitableFunction interface extended by both TableReadFunction and TableWriteFunction interfaces. Otherwise, non-serializable fields will be null after I/O function is deserialized.
class ReadFunction implements TableReadFunction {
@Override
public void init(Config config, TaskContext context) {
/* Initialize all transient fields here. */
}
}
class WriteFunction implements TableWriteFunction {
@Override
public void init(Config config, TaskContext context) {
/* Initialize all transient fields here. */
}
}Logging
Our recommendation is to:
- Avoid doing any informational logging in I/O functions that are typically
invoked extensively in Samza applications, e.g.
TableReadFunction.get[All]()TableWriteFunction.put[All]()TableWriteFunction.update[All]()TableWriteFunction.delete[All]()
- Log all initialization-related successes/failures occurring in overrides of
InitableFunction.init()to improve diagnosability.
Handling Client Exceptions and Retrying Failed Requests
Implementations of I/O functions for remote stores are likely to utilize a client object for communicating with their corresponding store endpoints. In this setup, it is possible for an I/O function to run into situations where the client it uses throws, e.g. in response to networking or logical errors.
We recommend:
- Catching all such errors, wrapping and throwing them in a
[
SamzaException] (https://github.com/apache/samza/blob/master/samza-api/src/main/java/org/apache/samza/SamzaException.java). - Attempting no retry in the face of client errors or failed requests. The intent of the current design of Samza Remote Table API is to handle retries at a higher and more abstract Remote Table level, which implies retrying is not a responsibility of I/O functions.
Batching
Samza Remote Table API can be configured to utilize user-supplied bath providers. You may refer to the Batching section under Remote Table for more details.
Caching
Samza Remote Table API can be configured to utilize user-supplied caches. You may refer to the Caching section under Hybrid Table for more details.
Rate Limiting
Samza Remote Table API offers generic rate limiting capabilities that can be used with all I/O function implementations. You may refer to the Rate Limiting section under Remote Table for more details.
Separate vs Combined Read/Write Implementations
It is up to the developer whether to implement both TableReadFunction and
TableWriteFunction in one class or two separate classes. Defining them in
separate classes can be cleaner if their implementations are elaborate and
extended, whereas keeping them in a single class may be more practical if
they share a considerable amount of code or are relatively short.